Cómo aprovechar la memoria de los proyectos en ChatGPT

OpenAI ha tenido un agosto muy activo: los modelos de pesos abiertos, GPT5, el nuevo plan Go para la India o ajustes varios en cuentas Free, Pro y Plus, entre otras cuestiones.
Un pequeño cambio también estrenado en agosto y no tan comentado ha sido que ahora los proyectos tienen memoria propia. Es decir, cuando creas un proyecto (ya sea para un trabajo concreto, un expediente o un cliente, por ejemplo) puedes indicar que las conversaciones desarrolladas en ese proyecto sólo recuerden lo hablado y compartido en el mismo, si tener en cuenta el resto de conversaciones.
El cambio parece inocente pero es relevante, ya que si queremos trabajar algo muy concreto, material sensible o un tema de largo plazo, hasta ahora los proyectos también tenían en cuenta el historial de chats y los recuerdos en general al margen de ese proyecto (aquí explicaba más en detalle cómo funciona la memoria de ChatGPT). Por tanto, todo se podía acabar mezclando y por ello degradando la respuesta.
Pero ahora podemos impedir que eso ocurra, de forma que todas las conversaciones generadas en ese proyecto estén 100% vinculadas al objeto y contexto del proyecto, no a los otros muchos temas tratados con ChatGPT.
Por ejemplo, digamos que quiero crear mi banco de cláusulas y posiciones negociadoras en contratos tecnológicos, con matrices de posiciones, argumentarios y checklists homogéneos por cliente o sector. De ese modo, podría señalar las instrucciones concretas y recuerdos del cliente o sector.
Por ejemplo, el Cliente X prefiere: ley/española; jurisdicción Madrid; inglés solo en anexos técnicos, cap de responsabilidad a 12 meses de fees, prohibido entrenar con datos del cliente salvo cláusula explícita; logs a 12 meses; auditoría anual y seguridad ISO 27001 o equivalente.
Realizadas esas especificaciones y habiendo añadido los correspondientes archivos también (hasta 40), el prompt de cada conversación podría ser algo como esto: “Compara este acuerdo de contrato/cláusula con mi estándar y produce tabla de diferencias, grado de severidad y propuesta de texto”.
Cada conversación lanzada en ese proyecto solo tendrá en cuenta esos archivos, esos recuerdos y esas conversaciones sobre exactamente el mismo tema. Por tanto, puede empezar a “aprender” mejor lo que nos interesa y no mezclamos con las memorias y recuerdos derivados de otras conversaciones (por ejemplo, sobre imágenes de Ghibli de las vacaciones, una película para ver en el cine o la guía de viajes de mi sobrino).
Yo por ejemplo he creado un proyecto nuevo para generar resúmenes ejecutivos de 1-2 páginas relativos a resoluciones, sentencias, guías, dictámenes o informes relevantes en protección de datos del sector turístico.
Lo llamo One Page Regulatorio.
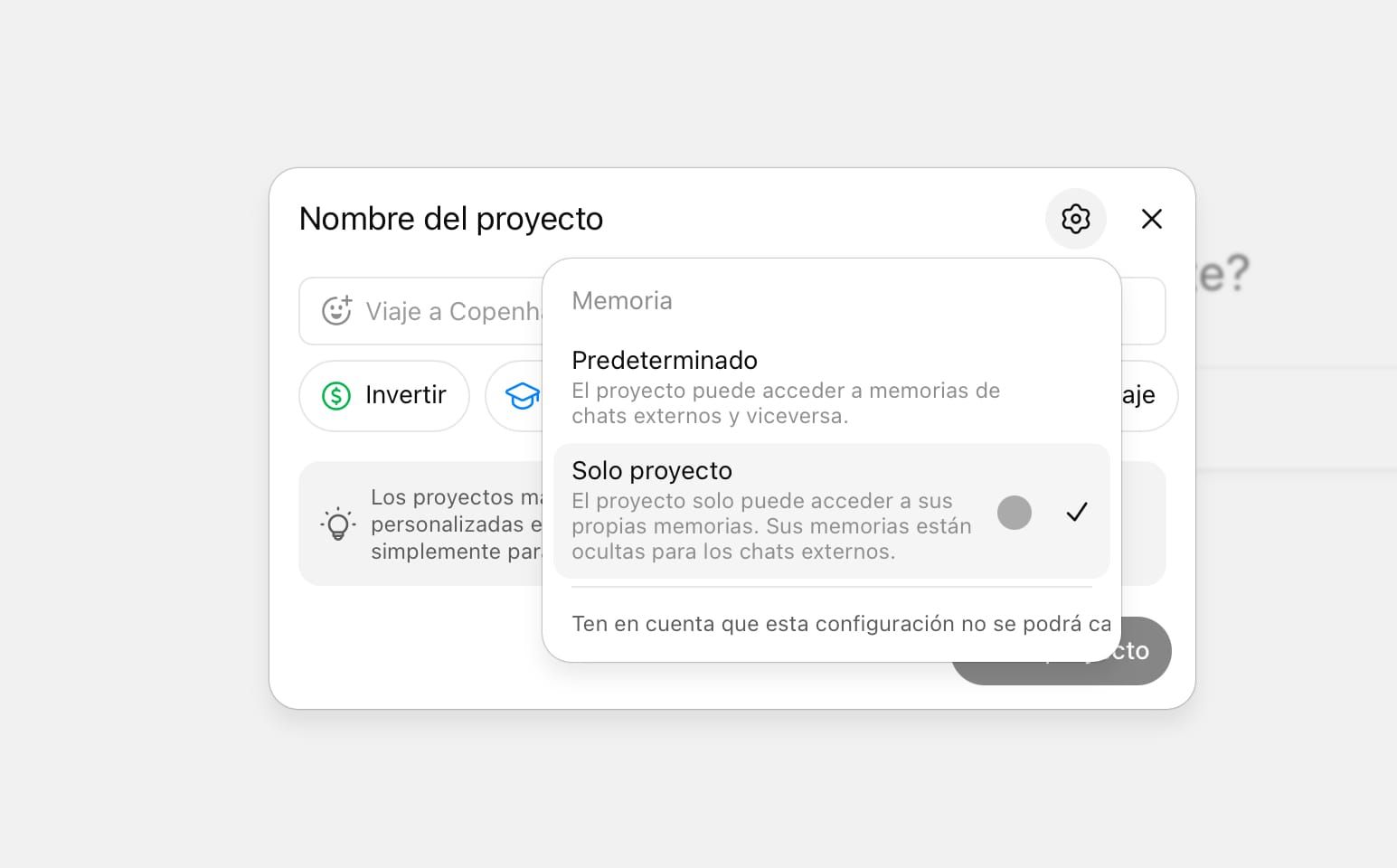
En el mismo he configurado al inicio que la memoria sea solo del proyecto.
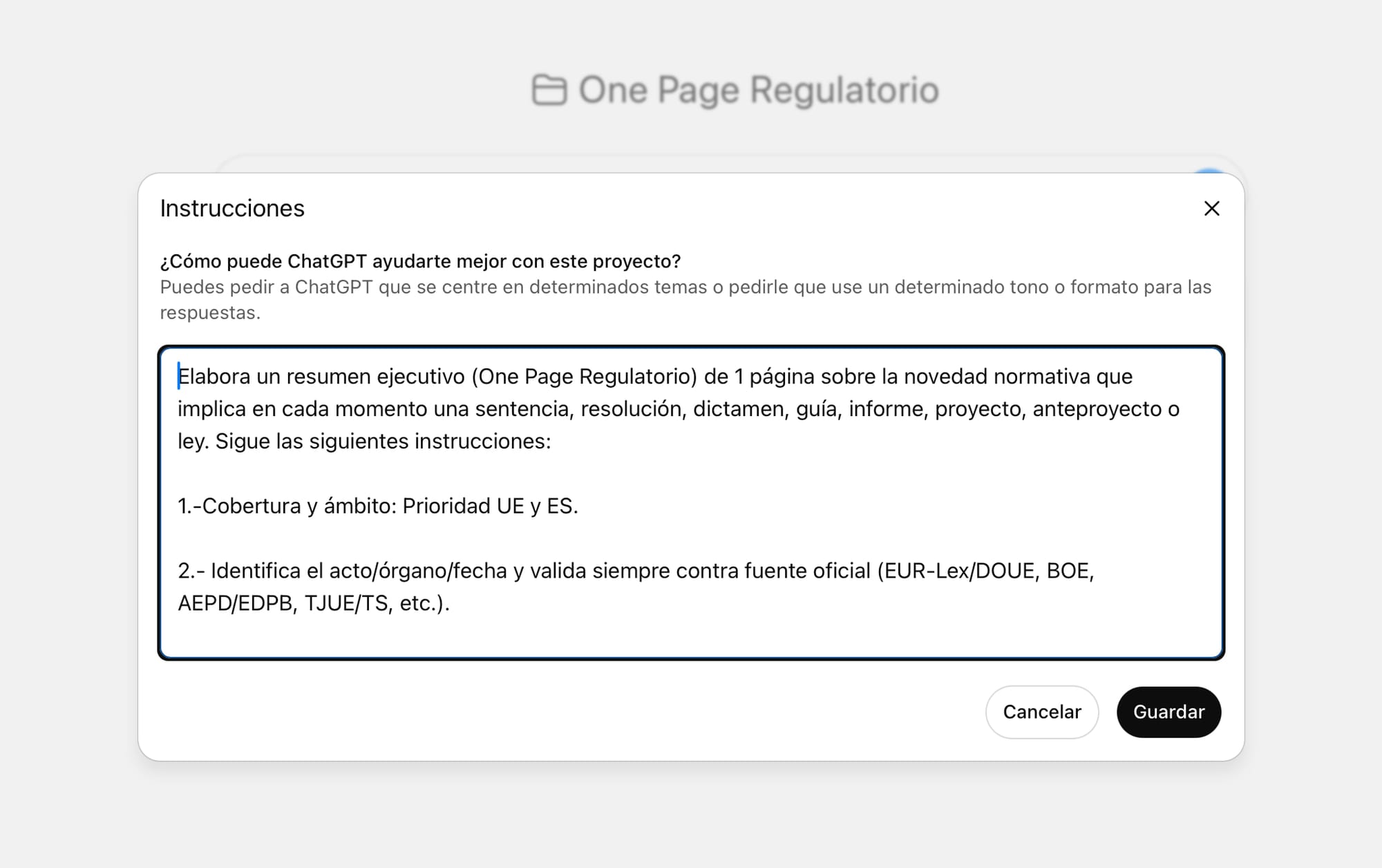
Lo cargo con los archivos que me interesan y defino instrucciones:
Añado una resolución reciente de la AEPD (sobre escaneo de DNI) respecto a la que querría obtener un resumen ejecutivo para enviar a potenciales interesados.
Y tenemos en 3 minutos nuestro resumen ejecutivo 🧐
La gracia es que mientras más usemos ese proyecto para el tipo de tarea indicada, más se debería reforzar la memoria y recuerdos en relación a la misma y cómo la queremos, sin intoxicaciones de otras peticiones. Por tanto, las opciones son múltiples y esto va más allá de un GPT, donde no se pueden crear memorias estancas.
Importante recordar que la activación de la memoria, sino es en cuentas Business (la antigua Teams) o Enterprise, implica que los datos compartidos entrenan a los modelos de IA.
Aquí las instrucciones indicadas, para el que quiera hacer pruebas con este caso de uso :
Elabora un resumen ejecutivo (One Page Regulatorio) de 1-2 páginas sobre la novedad normativa que implica en cada momento la sentencia, resolución, dictamen, guía, informe, proyecto, anteproyecto o ley adjunta. Sigue las siguientes instrucciones:
1.- Cobertura y ámbito: Prioridad UE y ES.
2.- Identifica el acto/órgano/fecha y valida siempre contra fuente oficial (EUR-Lex/DOUE, BOE, AEPD/EDPB, TJUE/TS, etc.).
3.- Formato de salida por defecto (máx. 1-2 págs.):
A. Qué ha pasado (acto, órgano, fecha, estado),
B. Por qué importa (novedad/umbral),
C. Impacto práctico (riesgos, obligaciones, costes),
D. Acciones propuestas (checklist con plazos y responsable tipo),
E. Fuentes verificadas (enlace oficial).
4.- Matriz de prioridad:
- Alta (TJUE/TS; guías finales AEPD/EDPB; sanciones >50k€; plazos <6 meses).
- Media (consultas públicas críticas; decisiones de NCA relevantes).
- Baja (discursos/notas sin efecto jurídico directo).
5.- Estilo: formal, numerado, sin especulación; si hay incertidumbre, indicarla expresamente.
6.- Genera el one page en un archivo Word.
Recuerda: nunca cites prensa si existe fuente oficial; valida siempre fecha y estado antes de resumir.
No recuerdes datos personales.
Recuerda en cada proyecto la taxonomía {IA, RGPD, LOPD, RIA, ENS}×{UE, ES}×{norma, guía, reglamento, resolución, sentencia}.
Dicho esto, ahí va la actualidad del 16 al 22 de junio en IA y Derecho (publicaré todas las semanas pendientes, las tengo recopiladas).
87 noticias sobre regulación, tribunales, propiedad intelectual e industrial, protección de datos, Legaltech y otros 🤖




