El agente de IA y sus formas

CALENDARIO de próximos CURSOS 😄
Uno de los conceptos que más confusión genera hoy al hablar de IA en el día a día legal es el de agente de IA. La palabra se ha puesto de moda y, como suele pasar, se usa para todo: desde un chatbot que responde cuatro preguntas hasta un sistema que redacta un escrito procesal de principio a fin.
Pero no son lo mismo.
Este año escribí ya sobre el prompt y sus formas: cómo una misma instrucción se despliega de maneras distintas (prompt suelto, GPT, proyecto, habilidad y plugin) según la frecuencia, la memoria y el contexto que necesites. Voy a intentar hacer el mismo ejercicio pero con los agentes. Porque también aquí hay capas, y entenderlas cambia mucho lo que puedes (o no) delegarles.
Qué es realmente un agente
Antes de las "formas", veamos la sustancia.
Aunque todavía no tenemos una definición definitiva (si bien la ISO/IEC 22989, en su cláusula 3.1.1, ofrece una primera aproximación) se puede decir que un agente de IA no es simplemente un modelo de lenguaje al que le escribes y te responde. Es una entidad que percibe su entorno, decide qué hacer y actúa sobre ese entorno de forma autónoma, en un ciclo continuo orientado a cumplir un objetivo.
Esta definición no es nueva: procede del marco que Stuart Russell y Peter Norvig consolidaron en 1995 en Artificial Intelligence: A Modern Approach, el texto que estableció la visión basada en agentes como marco organizador de toda la disciplina de la IA.
La diferencia con lo que ya conocemos es el grado de autonomía.
Es decir, un chatbot sigue un árbol de reglas fijas. Por ejemplo, un asistente conversacional (ChatGPT o Claude) genera texto, pero solo cuando se lo pides y normalmente sin encadenar acciones por su cuenta. Mientras tanto, la automatización robótica de procesos (RPA) ejecuta instrucciones preprogramadas, pero se rompe en cuanto cambia el formato.
Un agente de IA, en cambio, descompone un objetivo abstracto en subtareas, usa herramientas externas (bases de datos, APIs, lenguajes de programación o navegadores) y se adapta sobre la marcha sin necesidad de que le dirijas cada paso intermedio. Lo que separa a un agente inteligente del software ordinario es precisamente su capacidad de operar con cierto grado de autonomía, adaptabilidad y conducta orientada a objetivos, frente a un programa tradicional que recibe instrucciones explícitas y las ejecuta en secuencia.
La idea de fondo, en especial para los juristas, sería: a un asistente le das una instrucción para obtener una respuesta puntual (más o menos compleja), mientras que a un agente le delegas una meta. Es la diferencia entre decirle a un becario"Búscame el artículo 6 del RGPD" y decirle "Prepárame el borrador de respuesta a este requerimiento de la AEPD". En el primer caso esperas una respuesta puntual. En el segundo, esperas que se organice, investigue, redacte y te entregue algo revisable (en parte gracias a las muchas instrucciones que previamente le has enseñado o "codificado" para cada una de esas tareas).
Dicho esto, no todos los agentes son iguales. En verdad, ya Russell y Norvig clasificaban los agentes en cinco tipos de complejidad creciente, donde cada nivel añade una capacidad nueva: estado interno, representación de objetivos, evaluación de utilidad o aprendizaje.
Vamos de lo más básico a lo más sofisticado.
El agente de reflejo simple o el portero de discoteca
El escalón más básico es un agente de reflejo simple que decide únicamente con la percepción del momento, ignorando todo lo anterior. Por tanto, funciona con reglas del tipo "Si pasa X, haz Y", y carece por completo de memoria de estados pasados del mundo. Como resumen las propias transparencias del texto de Russell y Norvig, la acción no depende del historial de percepciones, solo de la percepción actual, por lo que no tiene requisitos de memoria.
Si lo llevamos a un ejemplo de protección de datos, sería ese filtro que mira el asunto de un correo entrante y, si encuentra las palabras "Ejercicio de derechos" o "Reclamación AEPD", lo desvía a una carpeta concreta o lo etiqueta. No entiende nada: solo reconoce la palabra y reacciona. El ejemplo de manual en la literatura es el termostato ("Si la temperatura está por debajo del umbral, enciende la calefacción; si está por encima, apágala").
Por tanto, es el portero de discoteca que mira los zapatos y decide 😅 Útil, rápido, pero incapaz de matices. Para muchas tareas de triaje documental básico, sin embargo, es más que suficiente.
El agente basado en modelos o el que recuerda la conversación
Subimos un escalón.
El agente basado en modelos mantiene un estado interno, una representación del mundo que le permite recordar cosas que ahora mismo no está percibiendo. Su diferencia clave respecto al agente simple es su capacidad de manejar entornos parcialmente observables: almacena descripciones del entorno no perceptible y actúa siguiendo reglas de condición-acción.
En materia legal, estaríamos hablando del asistente conversacional que gestiona varios turnos sin perder el hilo. Imagina una IA que recoge datos de un cliente para abrir un expediente de brecha de seguridad: si en el mensaje 3 mencionas que la fuga afectó a datos de salud, en el mensaje 7 el agente no te vuelve a preguntar qué tipo de datos eran. Lo recuerda y ajusta sus siguientes preguntas en consecuencia.
Es el primer agente con el que la interacción empieza a parecerse a hablar con alguien que presta atención. Sigue siendo limitado, pero ya no vive en el eterno presente del agente simple.
El agente basado en objetivos o el que planifica
Aquí se produce el salto cualitativo importante para el trabajo legal.
El agente basado en objetivos ya no reacciona: planifica. Además de la información de estado, dispone de información sobre situaciones deseables y toma en consideración eventos futuros. El mecanismo subyacente es, en esencia, búsqueda y planificación: proyecta secuencias de acciones para cerrar la brecha entre el estado actual y la meta.
Por ejemplo, le doy el siguiente objetivo al agente:"Valida que este contrato de encargado de tratamiento cumple con el RGPD". Un agente basado en objetivos no se limita a buscar la palabra "encargado" en el texto. Planifica: primero identifica a las partes, luego aísla las cláusulas de transferencia internacional, las contrasta con posibles reglas internas de cumplimiento y, si detecta desviaciones críticas, propone redacciones alternativas.
Esa capacidad de descomponer un objetivo en un plan secuencial es exactamente lo que diferencia a un agente útil de un buscador glorificado. Y es donde empieza a haber valor real para un despacho, porque mapea bastante bien cómo razona un jurista ante un encargo.
Por eso todos los modelos de IA desde o1 en ChatGPT, entre muchos otros, nos indican primero una planificación de las cosas que van a hacer, ofreciéndonos la opción de editarlo o aprobarlo.
El agente basado en utilidad o el que pondera
¿Y qué pasa cuando hay varios caminos posibles o cuando los objetivos compiten entre sí?
Ahí entra en juego el agente basado en utilidad. En este caso la diferencia es que los objetivos puros son binarios (se cumplen o no), mientras que una función de utilidad mapea un estado a un número real que representa un orden de preferencia, lo que resulta útil ante objetivos en conflicto. Además, en entornos estocásticos (los basados en el azar), el agente debe entender el riesgo, no solo el resultado.
Por ejemplo, digamos que usamos un agente de IA para análisis predictivo de litigios: el agente evalúa jurisprudencia histórica y estima si conviene seguir con una demanda o aceptar un acuerdo extrajudicial, sopesando matemáticamente tasas de éxito por juzgado, duración media del procedimiento y costas probables frente a la liquidez inmediata del acuerdo. No busca una solución, busca la mejor solución dadas unas variables en tensión.
Es el agente que no solo sabe llegar a la meta, sino que elige la ruta más conveniente cuando hay varias posibles.
El agente de aprendizaje o el que mejora solo
El siguiente nivel incorpora la capacidad de mejorar con la experiencia.
En el marco de Russell y Norvig, cualquiera de los tipos anteriores puede convertirse en un agente de aprendizaje, y el aprendizaje es precisamente el modo en que los programas llegan a existir y mejoran. Este tipo de agentes tienen cuatro piezas clásicas: un elemento de aprendizaje, un crítico que evalúa el rendimiento frente a un estándar, un elemento de rendimiento que selecciona acciones y un generador de problemas que propone escenarios nuevos para evitar el estancamiento.
Si lo llevamos al mundo legal, esto podría ser un sistema de recomendación de cláusulas que aprende de los integrantes del despacho. Por ejemplo, cada vez que los abogados corrigen, rechazan o validan sus sugerencias durante una negociación real, el agente reajusta sus pesos internos para proponer términos que reflejen mejor las prioridades comerciales de la firma. Con el tiempo, deja de sugerir cláusulas genéricas y empieza a sonar como otro miembro del equipo.
Por tanto, es el becario que, a base de que le corrijas, acaba escribiendo como tú. Con la diferencia de que este no se va a otro bufete a los dos años 👀
Las IA modernas, que mantienen contexto, razonan sobre la intención del usuario, acceden a herramientas externas y mejoran con la retroalimentación, se sitúan ya en esta categoría de agentes de aprendizaje.
Sistemas multiagente o tu nuevo equipo
En la cúspide de los agentes de IA están los sistemas multiagente y los agentes jerárquicos.
Aquí ya no hablamos de un agente, sino de varios agentes coordinándose: múltiples entidades especializadas que cooperan (o compiten) hacia objetivos comunes, organizadas a menudo de forma jerárquica, donde los niveles superiores toman decisiones estratégicas sobre resúmenes de datos y los inferiores ejecutan tareas técnicas detalladas.
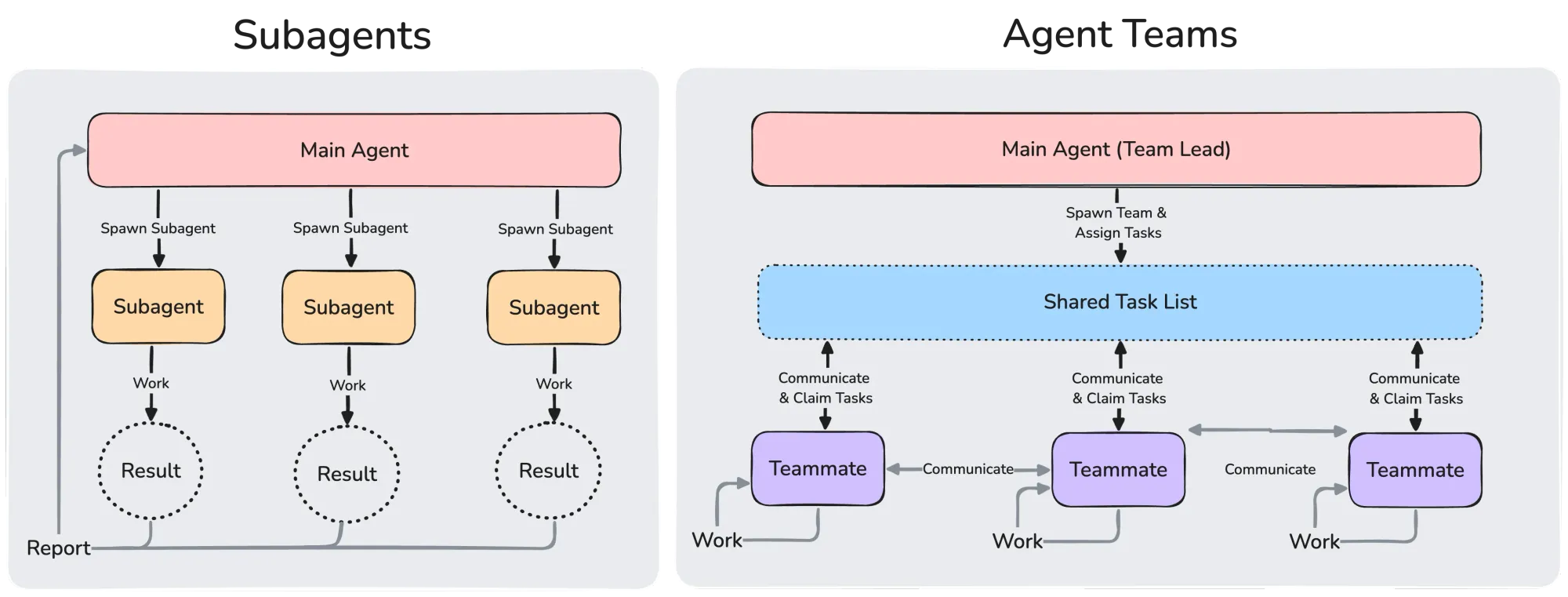
Por ejemplo, una operación de M&A o la due diligence de una cartera enorme de contratos. En ese caso, distintos agentes de IA podrían procesar información en paralelo (uno revisa cláusulas de cambio de control, otro obligaciones de protección de datos y otro propiedad intelectual), proporcionando un análisis integrado al abogado responsable. También puede haber un agente principal que coordine al resto, usando además diferentes modelos de IA (el principal el más avanzado, los subagentes más sencillos).
Es algo parecido al equipo de asociados, donde cada uno con su especialidad reporta al socio. Conviene apuntar que los sistemas multiagente tampoco son una invención reciente: es un área bien establecida dentro de la IA que la era de los agentes ha redescubierto.
Codex o Claude Code están basados en la idea de los múltiples agentes y en verdad muchos modelos modernos avanzados (Opus 4.8, Fable 5 o GPT 5.5) utilizan constantemente configuraciones basadas en multi-agentes.
Si juntamos las capas, la cosa queda así:
| Tipo de agente | Qué hace | Caso de uso legal |
|---|---|---|
| Reflejo simple | Reacciona a la percepción actual con reglas fijas | Etiquetado y triaje de correos por palabras clave |
| Basado en modelos | Recuerda y mantiene contexto | Intake conversacional de expedientes |
| Basado en objetivos | Planifica una secuencia hacia una meta | Auditoría automática de contratos |
| Basado en utilidad | Pondera y optimiza entre alternativas | Análisis predictivo de litigios |
| De aprendizaje | Mejora con la retroalimentación | Recomendación adaptativa de cláusulas |
| Multiagente / jerárquico | Coordina varias IA especializadas | Due diligence y operaciones de M&A |
Por tanto, la diferencia clave entre todos ellos es cuánta autonomía tienen y cuánto deciden por su cuenta. Algo que en Derecho no es una curiosidad técnica sino una cuestión de responsabilidad 🤖
Cómo se conectan al mundo y el matiz legal
Toda esta autonomía no sería muy útil si el agente no pudiera tocar nada fuera de su ventana de conversación. Aquí ha sido determinante el Model Context Protocol (MCP), el estándar abierto que Anthropic anunció y liberó como código abierto el 25 de noviembre de 2024 para conectar asistentes de IA con los sistemas donde viven los datos: repositorios de contenido, herramientas de negocio y entornos de desarrollo.
Desde entonces, es un protocolo que ha sido asumido por todos los grandes laboratorios de IA.
Dicho todo esto, entiendo que más de uno estará pensando, ¿cuántos agentes podría crear YA mismo?
Sin embargo, quizá la pregunta más correcta sería, ¿cuánta autonomía le dejo a esos agentes y dónde introduzco el control humano?
Obviamente la respuesta va a ser un clásico del mundo legal: DEPENDE, ya que no es la mismo etiquetar correos que presentar un escrito ante un juzgado.
Ahí deberemos hablar de gobernanza de la IA y 3 posibles modelos (al menos en teoría):
- Human-in-the-loop (HITL), donde el agente hace el trabajo pesado pero se detiene obligatoriamente en los puntos críticos para que un humano valide antes de ejecutar.
- Human-on-the-loop (HOTL), donde el agente opera de forma independiente y el humano supervisa a escala agregada mediante paneles y alertas.
- Totalmente autónomo, sin paradas de validación, quizá reservado a lo puramente administrativo y de nulo o mínimo impacto material (clasificar tickets, archivar correspondencia u homogeneizar formatos).
La regla básica al pensar en agentes de IA y sus formas es que cuanto mayor sea la autonomía y las posibles consecuencias jurídicas, por lógica más arriba debería estar el control humano.
En todo caso, la práctica puede llevarnos por caminos diferentes. Un reciente paper de Anthropic (abril 2026) titulado "Trustworthy agents in practice" afirma que la seguridad de un agente de IA tiene 4 capas: Modelo, Arnés, Herramientas y Entorno, y el proveedor del modelo (OpenAI o Anthropic) posee solo la primera. De hecho, los propios datos de Anthropic muestran que la supervisión humana en el bucle del agente (especialmente los de aprendizaje o los multi-agentes) ya ha fallado a escala de producción: el 93 % de las solicitudes de permiso son aprobadas SIN lectura, habiendo solo una tasa de aclaración del 16,4% en tareas complejas.
O lo que es lo mismo, y como dice Ilya Kabanov en relación al paper: "Los usuarios experimentados no están revisando las acciones antes de que ocurran. Están dejando que el agente corra e interviniendo cuando algo sale mal. Esa es la respuesta al incidente, no la supervisión".
Por tanto, en la práctica parece que estamos pasando del Human-in-the-loop (en el bucle) al Human-on-the-side (en los márgenes).
Moraleja
Igual que con el prompt, lo verdaderamente útil no es memorizar la lista de tipos de agente 🤓 Es entender sus distintos grados: un agente puede ser desde una IA simplona que etiqueta correos hasta una IA que coordina a varios "asociados" digitales en una due diligence o en una operación compleja de múltiples etapas que requiere 8-10 horas de trabajo.
Ahora bien, a medida que sube la autonomía, sube también lo que está en juego.
Por tanto, el abogado que trata a un agente simple como un gran planificar, lo sobreestima y puede llevarse un susto. Pero el que trate a un sistema multi-agente como si fuera un chatbot más, lo infravalora y puede llevarse un susto incluso mayor. Sin embargo, el que sabe en qué escalón está la herramienta que tiene delante puede calibrar exactamente cuánto delegar y dónde plantear el control humano.
De ese modo, la clave no estará en el agente, sino en saber cuánta correa vamos a darle 🤖
Jorge Morell Ramos
Dicho esto, ahí va la actualidad del 20 al 26 de abril de 2026 en IA y Derecho (publicaré todas las semanas pendientes, las tengo recopiladas).
47 noticias sobre regulación, tribunales, propiedad intelectual e industrial, protección de datos, Legaltech y otras.



